Page Not Found
Page not found. Your pixels are in another canvas.

A list of all the posts and pages found on the site. For you robots out there is an XML version available for digesting as well.
Page not found. Your pixels are in another canvas.
This website is still under development, please refer to my CV for more information about me
This is a page not in th emain menu
Published:
Grokking refers to a delayed generalization following overfitting when optimizing artificial neural networks with gradient-based methods. We show that the dynamic of grokking goes beyond the $\ell_2$ norm, that is: If there exists a model with a property $P$ (e.g., sparse or low-rank weights) that fits the data, then GD with a small (explicit or implicit) regularization of $P$ (e.g., $\ell_1$ or nuclear norm regularization) will also result in grokking, provided the number of training samples is large enough. Moreover, the $\ell_2$ norm of the parameters is no longer guaranteed to decrease with generalization when it is not the property sought.
Published:
Let’s suppose we’re training a model parameterized by $\theta$, and let’s denote by $\theta_t$ the parameter $\theta$ at step $t$ given by the optimization algorithm of our choice. In machine learning, it is often helpful to be able to decompose the error $E(\theta)$ as $B^2(\theta)+V(\theta)+N(\theta)$, where $B$ represents the bias, $V$ the variance, and $N$ the noise (irreducible error). In most cases, the decomposition is performed on an optimal solution $\theta^*$ (for instance, $\lim_{t \rightarrow \infty} \theta_t$, or its early stopping version), for example, in order to understand how the bias and variance change with the complexity of the function implementing $\theta$, the size of this function, etc. This has helped explain phenomena such as model-wise double descent. On the other hand, it can also be interesting to visualize how $B(\theta_t)$ and $V(\theta_t)$ evolve with $t$ (which can help explain phenomena like epoch-wise double descent): that’s what we’ll be doing in this blog post.
Published:
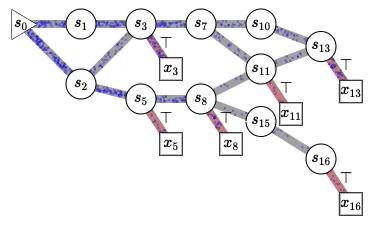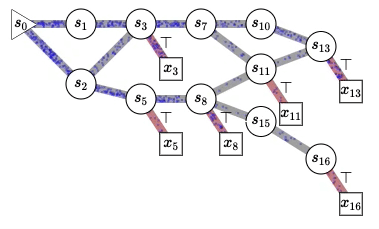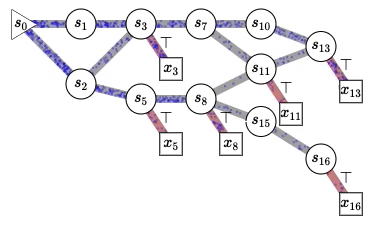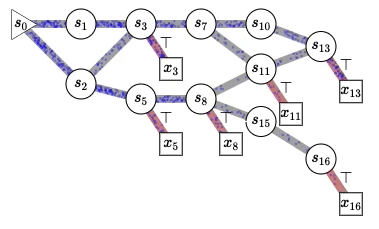
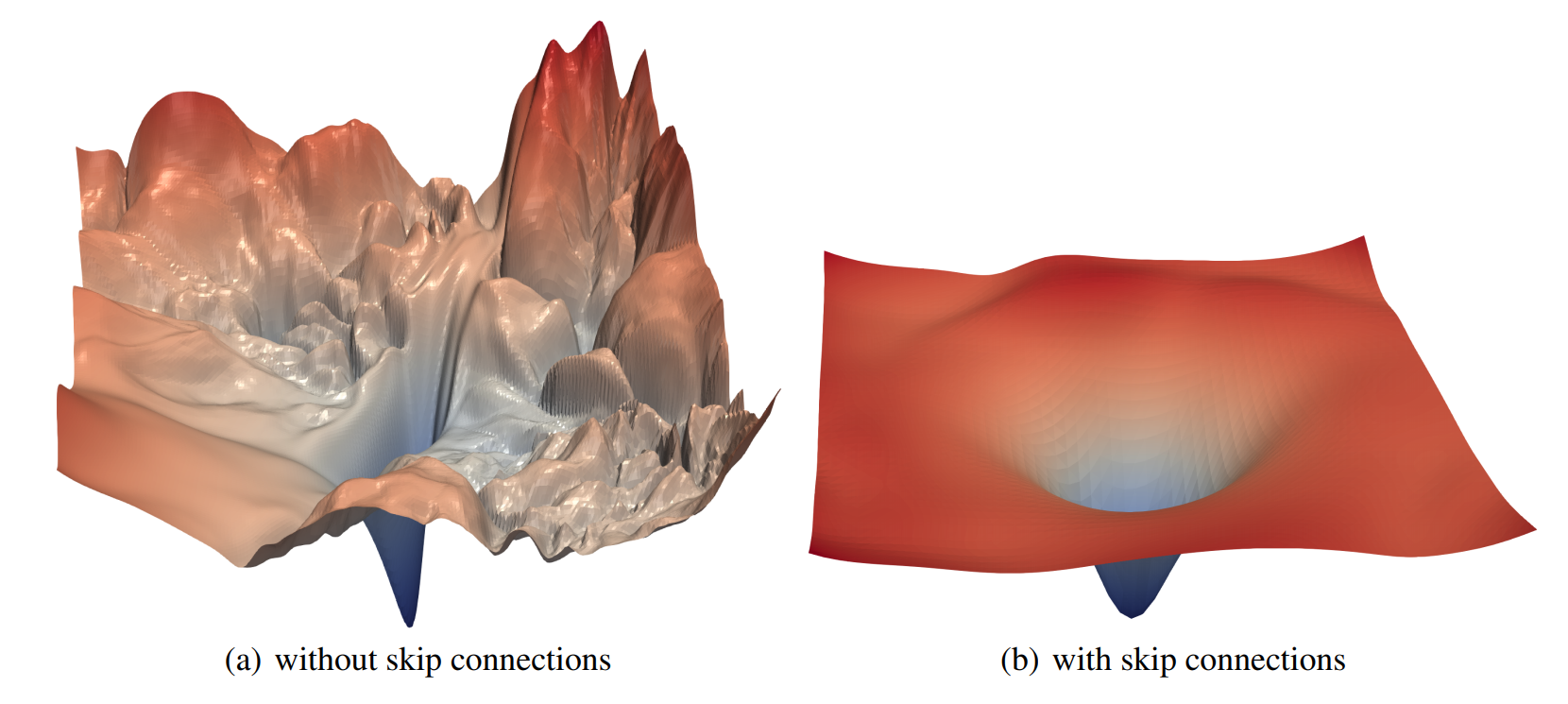
Published:
Published:
Published:

Pascal Jr. Tikeng Notsawo, Brice Nanda, James Assiene, 5th Black in AI Workshop @ NeurIPS, 2021.
Pascal Junior Tikeng Notsawo, IFT6512, Stochastic programming, Université de Montréal, 2023.
Dianbo Liu, Alex Lamb, Xu Ji, Pascal Jr. Tikeng Notsawo, Mike Mozer, Yoshua Bengio, Kenji Kawaguchi, In Thirthy-Seventh AAAI Conference on Artificial Intelligence, 2023.
Pascal Jr. Tikeng Notsawo, Hattie Zhou, Mohammad Pezeshki, Irina Rish, Guillaume Dumas, ICLR 2024 Workshop on Mathematical and Empirical Understanding of Foundation Models, 2023.
Tommaso Tosato, Pascal Jr. Tikeng Notsawo, Saskia Helbling, Irina Rish, Guillaume Dumas, Workshop on Large Language Models and Cognition, ICML, 2024.
Pascal Jr. Tikeng Notsawo, Guillaume Dumas, Guillaume Rabusseau, Forty-Second International Conference on Machine Learning (ICML), 2025.
Pascal Jr. Tikeng Notsawo, Guillaume Dumas, Guillaume Rabusseau, Preprint, 2026.
Marawan Gamal Abdel Hameed, Derek Tam, Pascal Jr Tikeng Notsawo, Colin Raffel, Guillaume Rabusseau, Preprint, 2026.
Published:

Published:

Yaounde, Cameroon, 2016, 2017
During my engineering training, I gave tutoring in mathematics, physics and chemistry to college students, at home (private) and in group.
Yaounde, Cameroon, 2017, 2018
During my training as an engineer, I prepared many students in mathematics and physical sciences (in short MSP, French system) for the entrance exams of the Grandes Ecoles in Cameroon.