Grokking Beyond the Euclidean Norm of Model Parameters
Published:
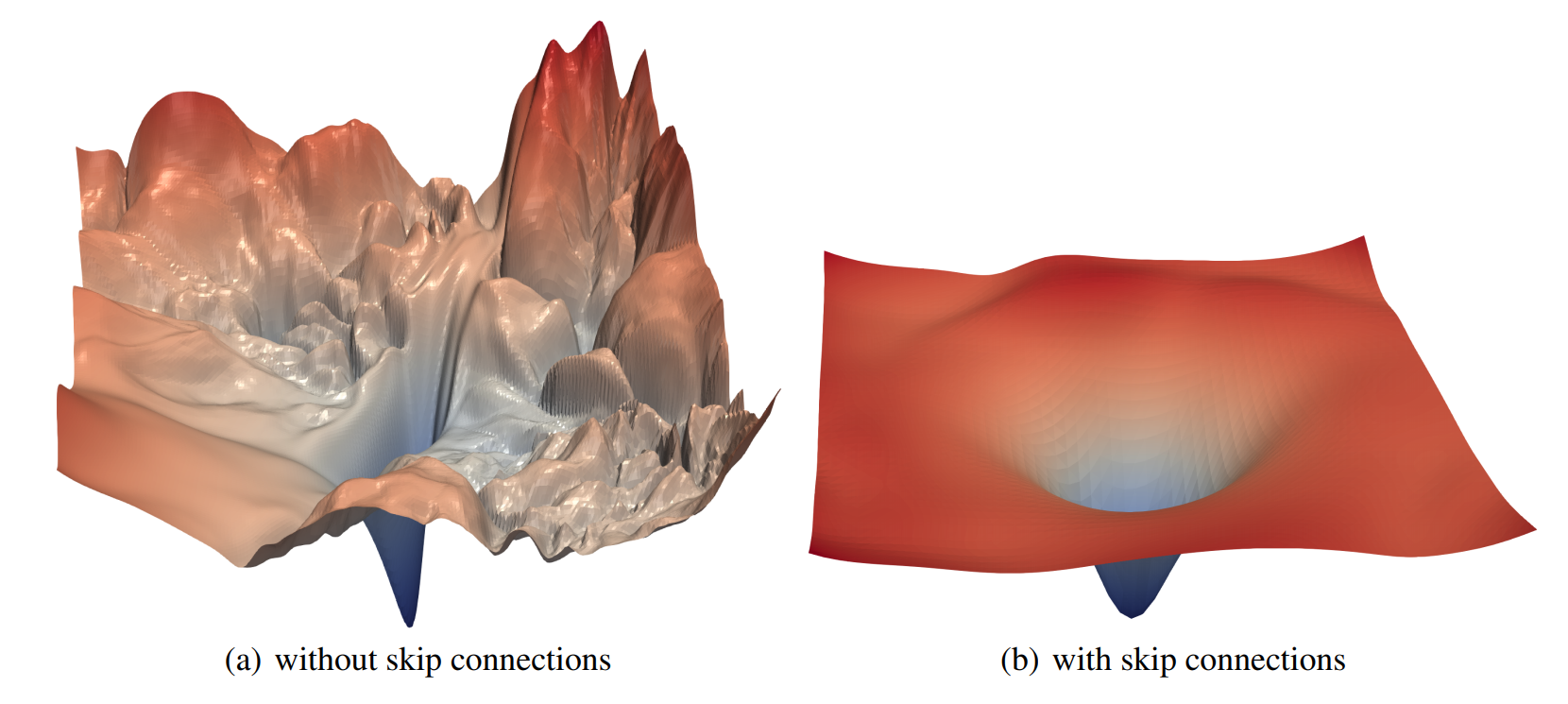
Grokking refers to a delayed generalization following overfitting when optimizing artificial neural networks with gradient-based methods. We show that the dynamic of grokking goes beyond the $\ell_2$ norm, that is: If there exists a model with a property $P$ (e.g., sparse or low-rank weights) that fits the data, then GD with a small (explicit or implicit) regularization of $P$ (e.g., $\ell_1$ or nuclear norm regularization) will also result in grokking, provided the number of training samples is large enough. Moreover, the $\ell_2$ norm of the parameters is no longer guaranteed to decrease with generalization when it is not the property sought.